

Easily Explained! Row_Number() vs. Rank() vs. Dense_Rank()

Got BDE?⚡️
Hi BDEs! ⚡️
Hope you all enjoyed the 31 days in a row of beginner SQL here in my newsletter and on YouTube because… PHEW I AM TIRED!! It was SO HARD to film 31 videos in a row and write corresponding newsletters. Like I literally spent at LEAST 1 hour per day on this campaign plus multiple weekend days filming. So much work… BUT I sure am glad I did because it warmed my heart so much to see so many people shouting me out and messaging me learning SQL. YOU ALL make it worth it, so thank you ❤️
In case you missed it and want to catch up, I made a homepage with ALL 31 lessons and videos here 🔥 Save this below:

⚡️If you’re new here:
💁🏽♀️ Who Am I?
I’m Jess Ramos, the founder of Big Data Energy and the creator of the BEST SQL course and community: Big SQL Energy⚡️. Check me out on socials: 🔗LinkedIn, 🔗Instagram, 🔗YouTube, and 🔗TikTok. And of course subscribe to my 🔗newsletter here for all my upcoming lessons and updates— all for free!
⚡️ What is Big SQL Energy?
🔗Big SQL Energy Intermediate is an intermediate SQL course designed to solve real-world business problems hands-on using realistic data and a modern tech stack. You’ll walk away with 2 SQL portfolio projects, portfolio building guidance, access to the Big Data Energy Discord community, and lots of confidence for you upcoming coding interviews! You also get access to all monthly events including masterclasses, office hours, and guest speakers. This course is all of the most important things I’ve learned on the job as a Senior Data Analyst in tech who grew from a $72K salary to over a $150K salary. And now I’m sharing it with YOU! It’s more than just another course— it’s a challenging program designed to upskill your SQL to the intermediate level, get ready to ace your live coding interviews, and build connections in the data community through the Discord and events.

⚡️ Social Highlights:
I asked ChatGPT to ROAST data analysts 😂 Read Here🔗

Is SQL Coding…? Here’s my 🔗response ⬇️
New YouTube 🔗Video!! ENTIRE 5 hour beginner SQL course 🎉 ⬇️
⚡️ Row_Number(), Rank(), & Dense_Rank() Easily Explained!
A lot of business problems rely on ranking methods in SQL:
Most recent order data per customer
First website session per user
Top 3 salaries per department
And the list goes on! More often than not, I’m looking for the most recent or first of something which requires a rank number of 1 (either in descending or ascending ranking order), but sometimes I need a different rank number like for question #3 above. And 9 times out of 10, Row_Number() suffices for a quick rank because I don’t usually care too much about ties, but sometimes you do have to consider tie handling which requires rank() and dense_rank(). Regardless of how little I use these compared to Row_Number(), it’s really good to understand the differences in these calculations because this is one of the most common SQL interview questions. We go over window functions including these in WAY more detail in 🔗Big SQL Energy Intermediate.
Seriously, interviewers LOVE asking about the differences between these, so you better know them well and be able to explain them!!
Row_Number()
Let’s start with Row_Number() since it’s the easiest to understand and the most widely-used. Row number provides a unique sequential number to each row and doesn’t account for ties/duplicates. It doesn’t repeat or skip any ranking numbers, and it’s non-deterministic, which means that you might not always get the exact same result since it arbitrarily handles ties. Check out the query and output below which ranks Taylor Swift songs on the 1989 album by danceability (rounded to 1 decimal place) descending, which means that the most (rounded) danceable songs will be at the top.
select
album,
"Song Name",
Danceability,
round(Danceability, 1) as Danceability_rounded,
row_number() over(/*partition by Album*/ order by Danceability_rounded desc) as danceability_rownumber
from
taylor
where Album = '1989'
;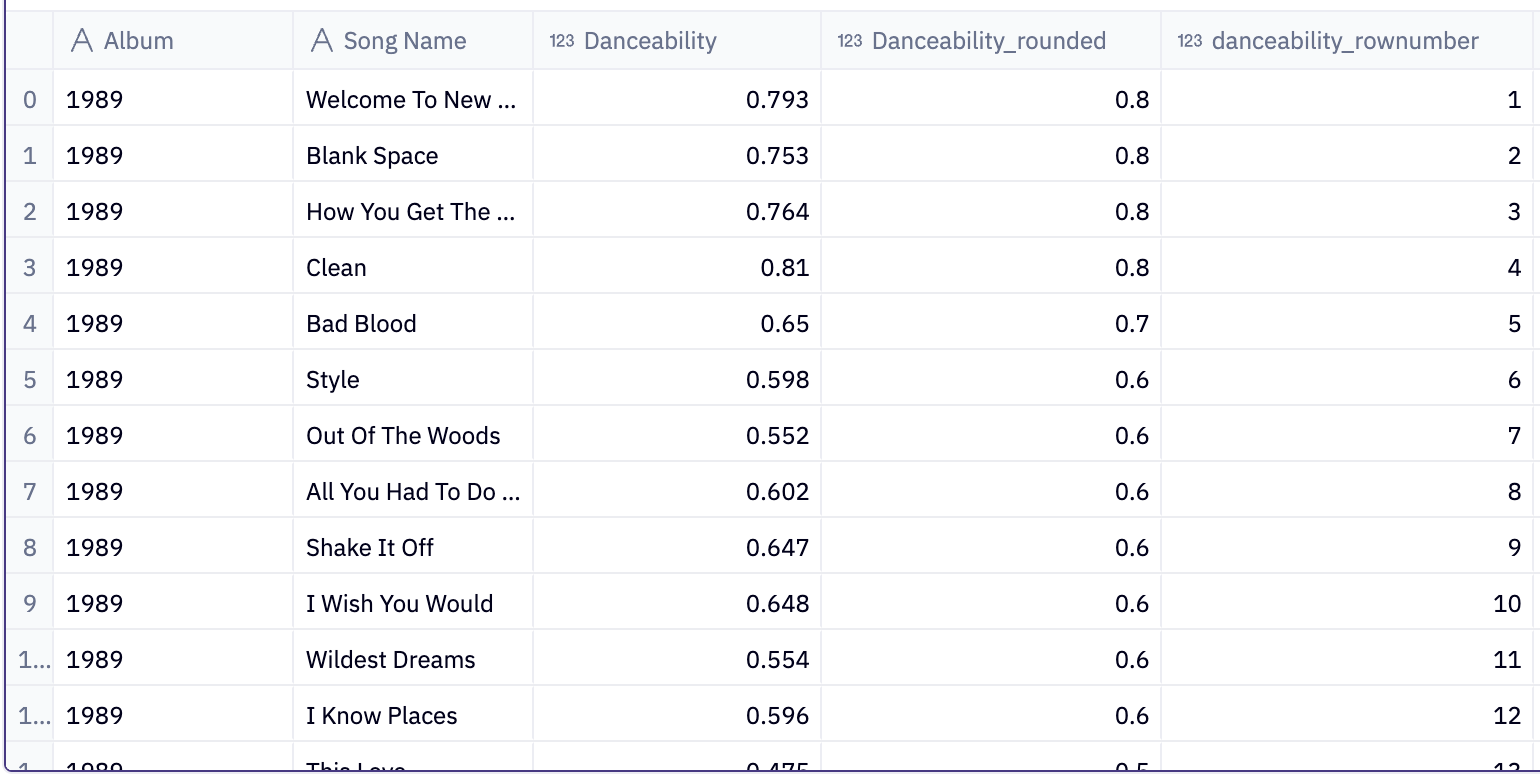
Even though there are ties for the rounded danceable score, each song has its own unique row number. Notice how the ties (0.8) are completely ignored.
Also note that I have commented out
partition by Albumfor simplicity. This is not needed since I filtered the query for the album 1989 and there’s only 1 album. If I removed the 1989 album filter and wanted to repeat this ranking process for each album, then I would use the partition by inside the window function before the order by to specify how to segment the data for the calculation.
Rank()
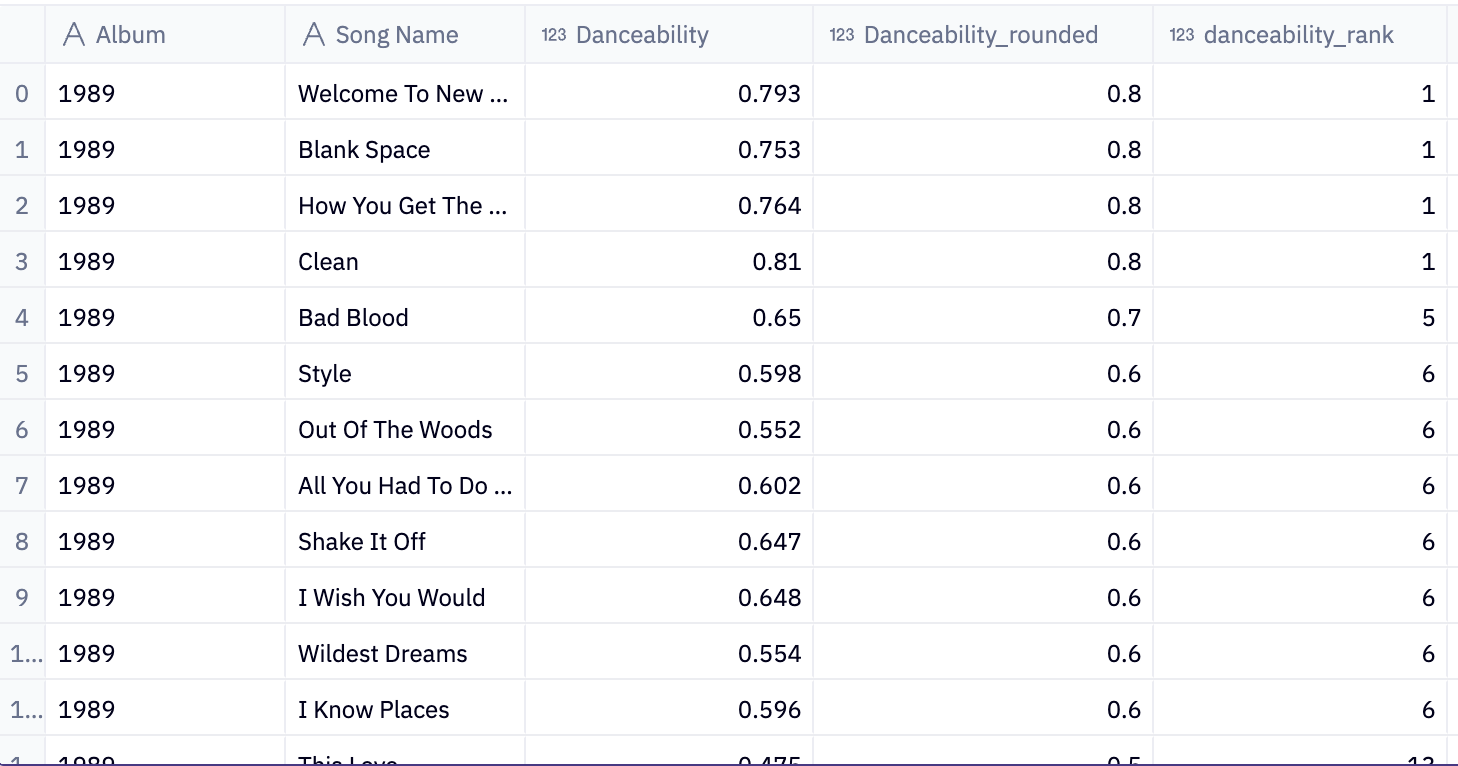
Now let’s see how Rank() is different. Rank() ranks each row in the dataset and allows for ties with duplicates. After a tie, it skips to the next row number, so the list of numbers will have gaps and won’t be complete if there are ties. Notice how all of the 0.8 rounded danceability scores are all tied for a rank value of 1, and then the next rank number after that is 5 to account for the 4 above it in ranking.
select
album,
"Song Name",
Danceability,
round(Danceability, 1) as Danceability_rounded,
rank() over(/*partition by Album*/ order by Danceability_rounded desc) as danceability_rank
from
taylor
where Album = '1989'
;
Dense_Rank()
Now for dense_rank()… it’s ALMOST like rank() except it doesn’t leave rank number gaps by skipping to the next row number after ties/dups. Dense_rank() uses the next rank number in the sequence after a tie. See the 0.8 values tied for 1 below? Then after that is 2 for the next rank value? This is how dense_rank() and rank() differ.
select
album,
"Song Name",
Danceability,
round(Danceability, 1) as Danceability_rounded,
dense_rank() over(/*partition by Album*/ order by Danceability_rounded desc) as danceability_denserank
from
taylor
where Album = '1989'
;
Put them all together!
I personally think it’s easiest to understand them all when they’re in the same query and output side by side.
Apologies for the ugly wrapped text format below. Find the commas to see the different rows in the code and copy and paste to your own environment.
select
album,
"Song Name",
Danceability,
round(Danceability, 1) as Danceability_rounded,
row_number() over(/*partition by Album*/ order by Danceability_rounded desc) as danceability_rownumber,
rank() over(/*partition by Album*/ order by Danceability_rounded desc) as danceability_rank,
dense_rank() over(/*partition by Album*/ order by Danceability_rounded desc) as danceability_denserank
from
taylor
where Album = '1989'
;
Knowing how to rank well in SQL is a MUST, but knowing how to explain the differences between row_number(), rank(), and dense_rank() are even more important when it comes to interviews. We go over window functions including these in WAY more detail in 🔗Big SQL Energy Intermediate, so don’t miss out on it!!
Here’s a YouTube vid on Row Number & Qualify: